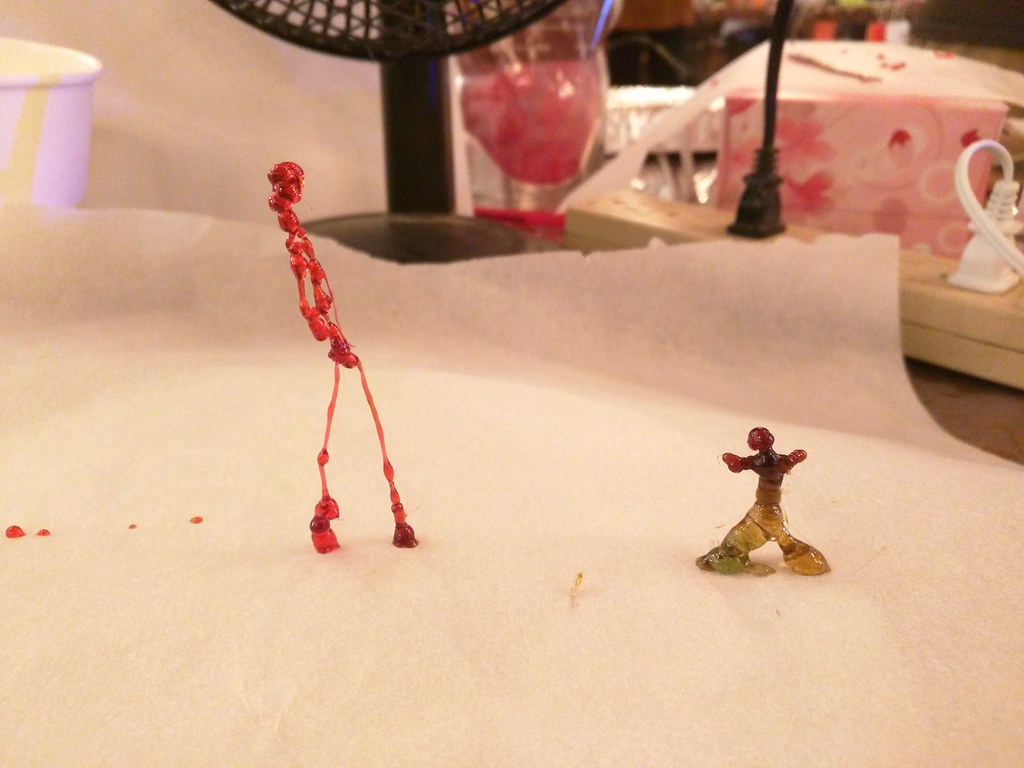Step 1: Buy candies. Different candies have different characteristics.
Among the various candies we tried, we suggest Jolly Rancher hard candy which melts at a lower temperature and best for people who wants to do rapid prototyping.
I liked mint candy and CakePlay Isomalt Nibs candy, as they works well to make skinnier and robust sculptures, but will take a lot of time.
Step 2: Melt the candies.
Put the candies in the toaster oven. We suggest 300-350 degrees to get the best melting.
Step 3: Take the candies out of the toaster and roll it into a filament.
The candy is ready when the liquid flows slowly when you tilt it back and forth. If it is too runny let it cool a bit before pouring. The candy is really hot so be sure to use tongs, tweezers, pot holders or high temperature gloves to move the candy.
Take the melted candies out of the toaster oven, put it on parchment paper and roll it to a very skinny stick. Best practice for making the filament stick: We poured and moved the candy / used toothpick to smear thick areas out. If you keep the thick areas as-is, it may not fit the glue gun. And be careful, it is hot! Let the candy cool in the parchment paper before removing.
Step 4: Put the candy filament in the glue gun, and create objects.
This is the most fun part :) Put the candy filament in the glue gun, and create 3D objects.
Pool++(Best In Show) (People's Choice Award)
They use Cameras and LIDARs to track the location of pool balls and cues, then run a physics engine to predict what will happen when you hit the ball, and then draw out these predictions using a laser.
The seismic vibrations of the 1906 SF earthquake are replayed in real time through a wave tank, with the water disturbances proportional to the strength of the earthquake at any time.
The Sorting Hat powered IBM Watson will do everything a Sorting Hat ought to except read the mind of the person wearing it. The wearer will speak into a microphone expressing characteristics of him or herself. The Hat will digest this information using a speech to text online resource, an online trained classifier and pronounce with enthusiasm the placement into which house the wearer is most appropriate.
They built a plastic chamber with an inlet for a fog machine and a window. By shining a planar laser beam into the chamber, it illuminates a single sheet of the swirling fog and were able to observe the flow of the fluid.
The team created a hoodie that'll allow people to feel more comfortable when walking at night, that will let you pipe EL wire through the hood and light up the wire.
The Mount Wilson archive of hand-drawn sunspot maps is a daily record that stretches back to 1917. Since each drawing is unique and hand-scanned, they were not well-suited to playing as a time series without substantial clean-up. This very long record of sunspot activity is both a unique piece of astronomical history and a powerful demonstration of the variety and timescales of activity on the surface of the sun.
Using a Pico Projector, cardboard and a fish-eye lens, the easy to make cardboard tower transforms any dark room into a journey into space. All that is needed is to download "Stellarium" which is an open-source application that shows detailed, interactive, live space data and visuals.
I visited the bio-hacking lab in Oakland- Counter Culture Labs several times recently and it's very interesting!
Introduction to Synthetic Biology
Some notes I took at "Introduction to Synthetic Biology" session:
In the past, bio-economy was something that only large universities and corporations with lots of capital can do, but recently it is changing, and some bio researchers are actually crowdfunded via Kickstarter and started their company.
In the electrical engineering world, we design, develop and make multiple iterations and build systems. In bio engineering, cells are encoded in genome. Just like we have "parts" list for engineering electronics like chips, we have parts list for organisms too. Parts can be any biological component that can be device or system (like metabolite, protein, regulatory DNA etc).
Clotho- Clotho is a framework for engineering synthetic biological systems and managing the data used to create them. You can author data schemas, run functions and algorithms, and tie Clotho into existing applications.
TinkerCell- TinkerCell is a Computer-Aided Design software tool for Synthetic Biology. It combines visual interface with programming API (Python, Octave, C, Ruby) and allows users to share their code with each other via a central repository.
CellDesigner- CellDesigner is a structured diagram editor for drawing gene-regulatory and biochemical networks.
In electric engineering we have "wiring diagrams", which is similar to deciphering / modeling structures of cellular networks, which is super hard, since it is dynamically changing with the conditions and environments.
You can learn more here, and I've added some reading list from the session down below.
Some notes and pictures I took about the various bio-hacking projects taking place in CCL I heard at "Mad Scientists and Biohackers Social meet up".
"The microbial fuel cell" project demonstrates electricity generated from yeast, and is powering the LED here. It generates an electrical current by diverting electrons from the electron transport chain of yeast. It uses a ‘mediator’ to pick up the electrons and transfer them to an external circuit.
"Open Insulin" project is developing the first open source protocol to produce insulin simply and economically. Their work may serve as a basis for generic production of this life-saving drug and provide a firmer foundation for continued research into improved versions of insulin.
There are currently about 387 million people worldwide living with diabetes. Meanwhile, there is no generic insulin available on the market despite great demand in poorer communities and regions of the world. As a result, many go without insulin and suffer complications including blindness, cardiovascular disease, amputations, nerve and kidney damage, and even death. Pharmaceutical companies patent small modifications to previous insulins while withdrawing those previous versions from the market to keep prices up. Additionally, research into improvements to insulin is encumbered by the subtle and difficult nature of the current standard protocols for insulin synthesis.
"In Stage 1, the team will insert an optimized DNA sequence for insulin into E. coli bacteria, induce the bacteria to express insulin precursors, and verify that human proinsulin has been produced. If we raise more than the minimum required for Stage 1, we will proceed to establish the protocols for cutting and folding the proinsulin into its final, active insulin form, and develop purification methods sufficient for research and potential pharmaceutical use. All protocols we develop and discoveries generated by our research will be freely available in the public domain. We will also be proactively investigating strategies to protect the open status of our work."
"Ghost Heart" project is using "decellularization", a tissue engineering technique designed to strip out all the cells from a donor organ, leaving nothing but the connective tissue that used to hold the cells in place. This "ghost organ" can then be reseeded with a patient's own cells, with the goal of regenerating an organ that can be transplanted into the patient without fear of tissue rejection.
"Real Vegan Cheese" project uses synthetic biology to engineer yeast to become milk-protein. Milk proteins are then combined with water and vegan oil to make "Vegan Milk" which is converted into "Real Vegan Cheese" through standard cheese-making processes.
Equipments
Various equipments at Counter Culture Labs.
Fermentation Station
This is the "fermentation station". Fermentation teams meet up every week, making their own konbuchas and various wines, some of them are super unique like onion wine and garlic wine.
Mushrooms
This is the room for growing mushrooms.
Equipment to blow the air equally to all areas for the mushrooms.
More readings
Some more readings from the Introduction to Synthetic biology session:
"Bacteria can sense their environment, distinguish between cell types, and deliver proteins to eukaryotic cells. Here, we engineer the interaction between bacteria and cancer cells to depend on heterologous environmental signals. We have characterized invasin from Yersinia pseudotuburculosis as an output module that enables Escherichia coli to invade cancer-derived cells, including HeLa, HepG2, and U2OS lines. To environmentally restrict invasion, we placed this module under the control of heterologous sensors. With the Vibrio fischeri lux quorum sensing circuit, the hypoxia-responsive fdhF promoter, or the arabinose-inducible araBAD promoter, the bacteria invade cells at densities greater than 10(8)bacteria/ml, after growth in an anaerobic growth chamber or in the presence of 0.02% arabinose, respectively. In the process, we developed a technique to tune the linkage between a sensor and output gene using ribosome binding site libraries and genetic selection. This approach could be used to engineer bacteria to sense the microenvironment of a tumor and respond by invading cancerous cells and releasing a cytotoxic agent."
"Synthetic gene networks can be constructed to emulate digital circuits and devices, giving one the ability to program and design cells with some of the principles of modern computing, such as counting. A cellular counter would enable complex synthetic programming and a variety of biotechnology applications. Here, we report two complementary synthetic genetic counters in Escherichia coli that can count up to three induction events: the first, a riboregulated transcriptional cascade, and the second, a recombinase-based cascade of memory units. These modular devices permit counting of varied user-defined inputs over a range of frequencies and can be expanded to count higher numbers."
"Organisms must process information encoded via developmental and environmental signals to survive and reproduce. Researchers have also engineered synthetic genetic logic to realize simpler, independent control of biological processes. We developed a three-terminal device architecture, termed the transcriptor, that uses bacteriophage serine integrases to control the flow of RNA polymerase along DNA. Integrase-mediated inversion or deletion of DNA encoding transcription terminators or a promoter modulates transcription rates. We realized permanent amplifying AND, NAND, OR, XOR, NOR, and XNOR gates actuated across common control signal ranges and sequential logic supporting autonomous cell-cell communication of DNA encoding distinct logic-gate states. The single-layer digital logic architecture developed here enables engineering of amplifying logic gates to control transcription rates within and across diverse organisms."
"The ghostlike photos—images of people, words and buildings—were made when the students exposed Petri dishes holding billions of genetically engineered E. coli to patterns of light. A new biological circuit in the E. coli gives them the ability to sense light and make black pigment. Each bacterium acts like a pixel on a computer screen, turning black when growing in the dark part of a projection and staying clear in the light."
TED talk about DIY bio :)
Ellen Jorgensen: Biohacking -- you can do it, too
I am totally new to bio hacking area, but now I realized that I joined a session called "Real Hackers Program DNA" by Reshma Shetty and Barry Canton from Ginkgo BioWorks back in 2009 at eTech! We chose DNA among the 3: DNA that makes the cells turn red, glow in the dark, or smell like banana (I chose glow in the dark). It was super fun, and I actually wrote a blog post about it in Japanese :)
It looks like there will be a workshop to make E.Coli smell like banana in the coming weeks... looking forward to join the workshop!
Omni Commons
Counter Culture Labs is part of "Omni Commons", which operates the whole building.
This is the entrance, I heard it was long used as a bar and was used later as a bookstore, now under renovation.
They also have a theater, which was used for showing movies on one of the days I visited.
"Material Print Machine" is an artist-run studio and bindery dedicated to the art of print and publishing. They have various printing machines and tools. Super cool.
They also have "Sudo Room" which is a hackerspace, yoga studio, poetry publisher, and many more.
Disclaimer: The opinions expressed here are my own, and do not reflect those of my employer. -Fumi Yamazaki